BibTeX形式に変換する
Pybliographerは書誌データベース管理ツー ルです。これはいくつかの書誌フォーマットをサポートしており GNOME 用の 快適なグラフィカルインタフェースを介して検索、編集、再フォーマットその 他が使用できる。
Pybliographerはその本質から多数の用途 (書誌検索者別 HTML を作成するなど)に拡張できる。これにはスクリプト例が 付いています。国際化、Medline サポート、LyXサポート、スピードアップ諸々 です。
PybliographerからPubMedの検索を行うこと ができ、その結果をインポートできる。
未検証だが、ここにメモっておく。
(setq bibtex-user-optional-fields '(("annote" "Personal annotation (ignored)") ("yomi" "Yomigana") ("location" "where it is (ignored)") ("memo" "Memorundum (ignored)") ))
perl-Tk が必要。
設定ファイル
起動すると
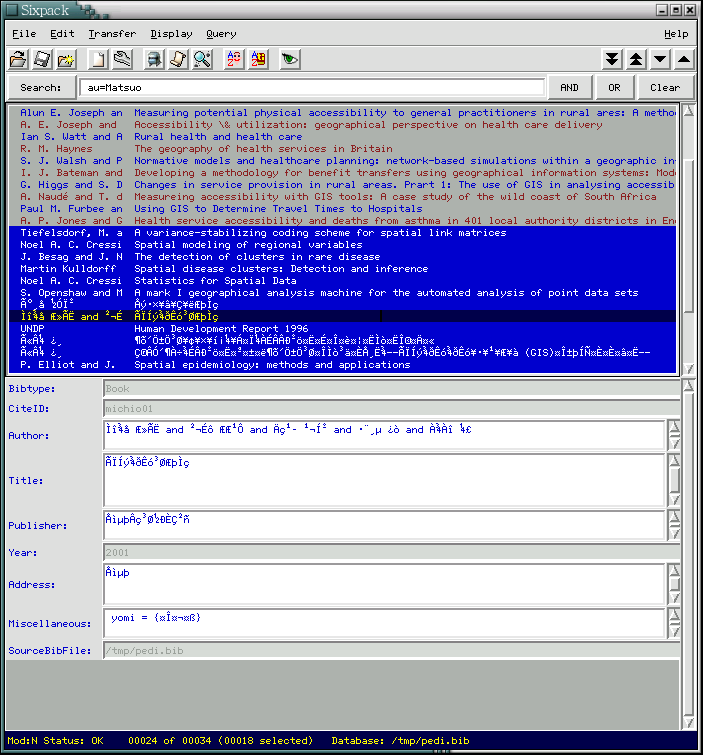
%0 [0 of 0]>
上記のようなプロンプトがでるので、helpでコマンドを参照し、適当にimport やshowで試す。
-1>%6 [0 of 0] /tmp/pedi.bib>show 25
del:
last: ,
# = 25
Bibtype = Article
CiteID = susumu03
Author = 谷村 晋
Title = 空間疫学アプローチは疾病対策にどのように役に立つか
Journal = 日本熱帯医学会雑誌
Year = 2003
yomi = {たにむら}
日本語もOKの模様。-guiオプションをつけて起動するとTcl/Tk版のsinpackが 起動する。日本語は化け化け。
既存のファイルが harvard スタイルを採用している場合、強制的に natbib
に移行できるようにするLaTeXスタイルファイル。harbardにあってnatbibにな
いコマンドを提供する。\usepackage{harvard}を
\usepackage{natbib}\usepackage{har2nat}で置換できる。ただし、読み込む
順番を気をつけなければいけない。
URMSBJの文献スタイルの例は、ここにあります。これは、Vancouverスタイルと呼ばれるもので、幸いにも(vancouver.bst [詳細])がCTANにあります。これを使って
\bibliographystyle{vancouver} \bibliography{使用するbibファイル名}
とすればOKです。
このvancuver.bstは、論文タイトルをbibファイルにかかれているとおりに出力します。
Lacetなどに投稿する際には文頭以外は小文字にした方がよいでしょう。自動的に論文タイトルの文頭以外を小文字にするには、vancouver.bstの546行目付近の
FUNCTION {format.title}
{ title
%%duplicate$ empty$ 'skip$
%% { "t" change.case$ }
%%if$
"title" bibinfo.check
}
この部分の%を削除します。
vancouver.bstでは、例えば、bibファイルの中に Donald E. Knuth と書かれ ていれば、 Knuth DonaldEと出力してしまいます。bibファイルの中を D. E. Knuthと代えれば、 Knuth DE と本来の出力をします。vancouver.bstを 編集して、Donald E. KnuthでもD. E. Knuthでも Knuth DEと出力するように しましょう。vancouver.bstの467行目
"{vv~}{ll}{ ff{}}{ jj}"
を
"{vv~}{ll}{ f{}}{ jj}"
と編集します。
2006年11月 9日現在の最新バージョンは0.37 モジュールは下記の通り
| モジュール名 | 説明 |
|---|---|
| Text::BibTeX | interface to read and parse BibTeX files |
| Text::BibTeX::BibFormat | formats bibliography entries |
| Text::BibTeX::BibSort | generate sort keys for bibliographic entries |
| Text::BibTeX::Entry | read and parse BibTeX files |
| Text::BibTeX::File | interface to whole BibTeX files |
| Text::BibTeX::Name | interface to BibTeX-style author names |
| Text::BibTeX::NameFormat | format BibTeX-style author names |
| Text::BibTeX::Structure | provides base classes for user structure modules |
| Text::BibTeX::Value | interfaces to BibTeX values and simple values |
解説はCTANのText-BibTeX-0.37を参照する。
参考になりそうな http://doesen8.informatik.uni-leipzig.de/~david/reads/reads.pl から抜 粋
use Strict; use Text::BibTeX; $bibfile = new Text::BibTeX::File "reads.bbl"; #foo.bib #$newfile = new Text::BibTeX::File ">newfoo.bib"; my $listAsHTML; my %keywordsHash; my %titleWordsHash; while ($entry = new Text::BibTeX::Entry $bibfile) { next unless $entry->parse_ok; # hack on $entry contents, using various # Text::BibTeX::Entry methods # print "ok?\n"; my $uwEntryAsHTML; my $key; my $author; my $title; my $year; my $url; my $booktitle; my $journal; my $address; my $keywordsString; my @keywords; my @titleWords; # split title with spaces # better syntax maybe:? # if ( $entry->exists ('title') ) { $title = $entry->get ('title'); } @authors = $entry->split ('author'); $key = $entry->key(); $author = $entry->get ('author'); $year = $entry->get ('year'); $title = $entry->get ('title'); $url = $entry->get ('url'); $booktitle=$entry->get ('booktitle'); $journal = $entry->get ('journal'); $address = $entry->get ('address'); $keywordsString = $entry->get ('keywords'); # inverted keyword listing @keywords = split(/, /,$keywordsString); foreach (@keywords) { my $currentIDs = $keywordsHash{$_}; $keywordsHash{$_} = $currentIDs . " " . $key; } # inverted title word listing (the same as above) @titleWords = split(/ /,$title); @titleWords = map(lc, @titleWords); # all to lowercase # within nicer? no, here. foreach (@titleWords) { $_ = nicer($_); $_ = stem($_); # porter stemmer # if word has already IDs/keys, get them my $currentIDs = $titleWordsHash{$_}; # add new ID/key to list of IDs $titleWordsHash{$_} = $currentIDs . " " . $key; } # to combine both journal and booktitle under one category to use with "In: " if (length($journal) > 0) { $within = $journal; } else { $within = $booktitle; } # whether we have a PDF or something else my $linktype; if (substr($url, length($url)-4) eq ".pdf") { $linktype = "pdf"; } else { $linktype = "link"; } # use url als linktype (forget the stuff ahead) $linktype = $url; # foreach(@authors) { print "$_, "; } # print "$author ($year) $title <$url>\n"; $uwEntryAsHTML = "<div id=\"$key\" class=\"BibItem\">\n<uw:publication>\n"; $uwEntryAsHTML.= "<span class=\"Author\"><uw:author>$author</uw:author></span>"; $uwEntryAsHTML.= "<span class=\"Year\"> (<uw:year>$year</uw:year>)</span>"; $uwEntryAsHTML.= "<span class=\"Title\"><uw:publicationTitle>$title</uw:publicationTitle></span>"; if ($within) { $uwEntryAsHTML.= "<span class=\"TitleSecondary\"><uw:forumName>$within</uw:forumName></span>"; } if ($address) { $uwEntryAsHTML.= "<span class=\"Address\"><uw:forumLocation>$address</uw:forumLocation></span>"; } $uwEntryAsHTML.= "<span class=\"URL\"><uw:file><a href=\"$url\">$linktype</a></uw:file></span>\n"; $uwEntryAsHTML.= "</uw:publication>\n</div>\n\n"; $listAsHTML.= $uwEntryAsHTML; # $entry->write ($newfile); }
use Text::BibTeX; $bibfile = new Text::BibTeX::File "foo.bib"; $newfile = new Text::BibTeX::File ">newfoo.bib"; while ($entry = new Text::BibTeX::Entry $bibfile) { next unless $entry->parse_ok; Text::BibTeX::Entryのメソッドを使って処理 $entry->write ($newfile); }
use Text::BibTeX; $entry = new Text::BibTeX::Entry;
preserve_valuesフラグを1に設定。これで、値を取り出すときに、文字列では なくText::BibTeX::Valueオブジェクトになっている。
$entry->parse ($filename, $filehandle, 1);
値を取り出す。文字列ではなくText::BibTeX::Valueオブジェクトになってい ることに注意。
$value = $entry->get ($field);
Valueオブジェクトの処理
@all_values = $value->values; $first_value = $value->value (0); $last_value = $value->value (-1);
#!/usr/bin/perl use strict; use Text::BibTeX; my $bibfile = new Text::BibTeX::File 'test.bib' # open file or die "test.bib: $!\n"; my $entry; while (my $entry = new Text::BibTeX::Entry $bibfile) { next unless $entry->parse_ok; print $entry->key(), "=>"; print $entry->get ('title'), "\n"; }
$ perl bibtext.pl seki2002=>岡山県下における診療科別医療施設の分布と年次推移 uphoff04=>{Are influenza surveillance data useful for mapping presentations} lexical buffer overflowed (reallocating to 4000 bytes) odoi04=>Investigation of clusters of giardiasis using GIS and a spatial scan statistic brody04=>{Breast cancer risk and historical exposure to pesticides from wide-area applications assessed with GIS}
{}がついているのは、2重括弧になっているデータだから。日本語大丈夫っぽ い。どうやら、簡単にbibファイルをparseできそうなので、研究業績書自動作 成システムができそう。特定の項目を削除するPerlスクリプトでも手始めに書 くか。
研究業績書の自動作成システムは、perlでTeXの雛形を吐いて、その中にbibファ イルからの出力を混ぜる。bibファイル以外の部分は、\include{}で別ファイ ルとして書くようにする。科研費LaTeXなみにうまくいく。
CTANにあるlistbibは、bibファイルの一覧を作成するスタイルファイルとプロ グラム。platexやjbibtexに対応させるために、一部変更する必要がある。
1. テンプレートファイルであるlistbib.texの\begin{document}直下に、 \bibliography{jplain}を追加する。これがないと、listbib.bstを読みに行き、 エラーになる。 1. シェルスクリプトlistbibのlatexをplatexに、bibtexをjbibtexに書き換え る 1. デフォルトの出力dviは、listedbibs.dviになっている

crossref の仕様がbstごとに異なり、複数のエントリからcrossrefされている
エントリは、それ自体が引用されていなくても、jplainやjunsrtの場合、文献
リストに並ぶ。
jpainやjunsrtだと

のように引用していない、crossrefされている元のエントリが、 [4] として出現
する。さらに、 [1] や [2] の項目の中に [4] が入れられる。
jeconだと

のように、元のエントリが出現するが、文献リストに引用記号が埋め込まれる ことはない。
crossrefされる参照元が1回だけ読み出されるときは、参照しているエントリの 中に入れ込まれるが、複数回の場合は、入れ込まれずに、文献リストに文献と して追加される。ややこしい。業績集をつくるときは、stringsで逃げた方がい いのかも。美文書入門では、coressrefがややこしくなった場合、noteを代わり に使うように書かれている。
http://gpapers.org/ GnomeベースのPDF管理ソフト。iTunesのPDF版と考えれば よいそうだが、iTunesが未だによく分からない。
$ sudo apt-get install gpapers パッケージリストを読み込んでいます... 完了 依存関係ツリーを作成しています 状態情報を読み取っています... 完了 パッケージ gpapers はデータベースには存在しますが、利用できません。 おそらく、そのパッケージが見つからないか、もう古くなっているか、 あるいは別のソースからのみしか利用できないという状況が考えられます E: パッケージ gpapers にはインストール候補がありません残念。
BibTeXとは直接関係がないが、高機能な文献管理ソフトで、Firefoxのプラグイン。
jauthor や jtitle などを使う。Jecon.bstで有効。
@Book{fujita99jp:_spatial_econom, author = {Masahisa Fujita and Paul R. Krugman and Anthony J. Venables}, title = {The Spatial Economy}, publisher = {MIT Press}, address = {Cambridge, MA}, year = 1999, jauthor = {小出博之}, jtitle = {空間経済学}, jpublisher = {東洋経済新報社}, jyear = 2000 }
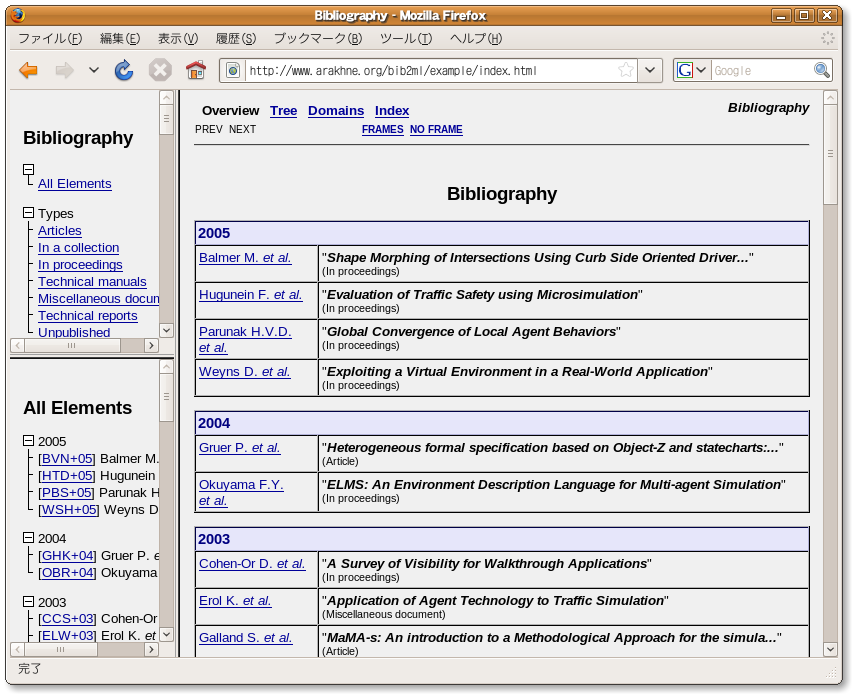
bibファイルからデータベース的なHTMLを作成するユーティリティ。bibファイルに書かれた文献をWWWブラウザで対話的に閲覧できるようになる。